Si la programmation est une activité déjà bien complexe
lorsque l’on travaille seul, la difficulté est largement amplifiée quand le
programme nécessite d’y travailler à plusieurs, car ce dernier cas nécessite en
général une architecture divisée en modules à périmètre restreint pour
permettre une bonne séparation des concepts.
Bien que ce type d’architecture soit souvent mis en
œuvre, l’interdépendance entre les modules constitue rapidement le point faible
qui oblige les développeurs à bafouer toutes bonnes pratiques de séparations pour
arriver à leur fin.
Dans cet article, je
vais traiter d’une solution évoluée de « Transformation de données »
pour garantir à votre architecture modulaire de rester le plus intègre possible
au niveau des principes SOLID.
Read the english version of this article on CodeProject
Read the english version of this article on CodeProject
Introduction
La séparation des parties d’un logiciel en plusieurs couches
ou modules est quelque chose de très répandu dans le monde du développement.
Cette pratique qui est censée faciliter la maintenabilité,
l’évolutivité et la testabilité du code possède plusieurs pièges dont le plus
classique consiste à créer de l’interdépendance lorsqu’il est nécessaire de
manipuler des objets à la frontière des modules.
Cette problématique est d’autant plus grande que la plupart
des Framework, outils et exemples poussent les développeurs à tomber dans ces
pièges architecturaux qui semblent être pour le néophyte pratiquement
inévitables !
Cet article va traiter d’une architecture spéciale dans laquelle
la transformation de données jouera un rôle important. Cette mécanique
permettra de mettre en place une parfaite séparation entre vos modules tout en
permettant une communication efficace.
La dérive d’une architecture
Pour vous exposer les problèmes les plus fréquemment rencontrés
sur le terrain, prenons le cas classique d’une application de gestion avec une
architecture en 3 couches :

La couche présentation contient le code lié aux vues, la
couche business le code qui concerne la logique métier (règles de validation,
entités, workflow, …) et la couche data le code permettant d’interagir avec une
base de données.
Tout cela semble apporter une bonne séparation dans la
théorie, mais comment ça se passe la plupart du temps ?
En général dans une application ayant ce type d’architecture,
ceux qui travaillent la couche DAL ont la responsabilité de fournir et
enregistrer des objets business dans la base de données. Il est donc nécessaire
pour eux de référencer la couche BLL afin de pouvoir les manipuler à leur aise.
Puis les développeurs du DAL se rendent rapidement compte
que leur vie sera largement facilitée s’ils utilisent un Framework pour
interagir avec leur base de données. Et comme la plupart des framework modernes
(comme entity framework) manipulent des « entités » auto générées à
partir du schéma de données, il semble donc beaucoup plus judicieux pour eux
d’utiliser ces entités en tant qu’objets métiers.
Surtout lorsque :
- Le framework possède un système de détection automatique des changements qui se base sur les instances de classes.
- Le framework permet de travailler avec des objets dit POCO censés donner la possibilité de faire des classes libres de toutes les contraintes liées au schéma de données.
Le choix est donc très rapidement prit : la couche BLL
possédera des entités générées par le framework qui permet de manipuler la base
de données.
Passons maintenant à la couche « Présentation ».
Ceux qui ont la charge de développer cette partie doivent
permettre aux utilisateurs de manipuler les objets métiers (clients, factures,
pièces, tableaux de bord, états de workflow, …) depuis des composants
graphiques parfois très complexes (tableaux croisés dynamiques, calendriers,
listes évoluées, indicateurs, etc.)
Heureusement pour eux, il existe beaucoup de composants de
ce type sur le marché, et la plupart d’entre eux permettent de se lier
directement à des sources de données.
Pour cela, la couche présentation a donc besoin de connaitre
les types d’objets qu’elle sera amenée à manipuler. Il est donc nécessaire de
référencer la couche BLL à la couche présentation.
Mais mettre en place une interface graphique ne se limite
pas seulement à dessiner ou arranger des composants graphiques entre eux. Il
faut aussi du code pour manipuler les objets afin de les rendre présentables.
Les design pattern permettant de traiter ce sujet (MVC, MVP, MVVM, …) semblent
avoir besoin d’accéder aux objets présents dans la BLL. Il est donc très
fréquent de retrouver du code d’IHM qui manipule directement ces entités.
On passe donc d’un système théoriquement parfaitement séparé
à quelque chose qui dans la pratique ressemble à ceci :

Les choix techniques de communications entre nos modules ont
conduit notre système à devenir quelque chose de fortement inter dépendant.
Certes, si l’on regarde le projet d’un point de vue
arborescence, tout semble bien séparé, mais un rapide graph de dépendance
montrera que les différentes DLL censées représenter les couches du logiciel sont
en réalité des sortes de dossiers dans lesquelles le code n’est rangé que parce
que cela parait logique.
Si quelqu’un a le malheur de vouloir revoir l’architecture,
il se fera très rapidement opposé le fait qu’il est impossible de faire du
remaniement de code pour cause d’enchevêtrement technique, et pour cause :
les instances des entités métiers sont directement utilisées par le framework
d’accès aux données, et sont manipulées directement par les composants
graphiques ! Cette pratique semble d’autant plus légitime que beaucoup
d’exemples de code présents sur MSDN, ou d’autres sites, mettent en avant ces
techniques pour des soucis de simplicité. Seulement les débutants prennent ce
code pour argent comptant, et ne se rendent pas toujours compte des conséquences
néfastes que cela apporte, comme la non testabilité et le couplage fort qui
freinent fortement l’évolutivité du logiciel et favorise les bugs par effets de
bords.
Revenons aux fondamentaux
La séparation du logiciel en plusieurs unités appelées « couche » ou
« module » vient du besoin de pouvoir isoler les différents domaines
de responsabilités de notre système pour servir plusieurs objectifs :
- Pouvoir travailler sur un domaine sans impact majeur sur les autres domaines.
- Pouvoir substituer l’implémentation d’un domaine par une autre implémentation.
- Pouvoir tester chaque domaine de manière indépendante, selon ses spécificités techniques
Une architecture en couches verticales n’est donc pas très
adaptée.
Pour servir tous ces objectifs, il est nécessaire en premier
lieu de remplacer l’architecture en couches verticales par quelque chose de
plus logique.
Commençons par faire un petit diagramme de Venn afin d’avoir
un aperçu de notre besoin :
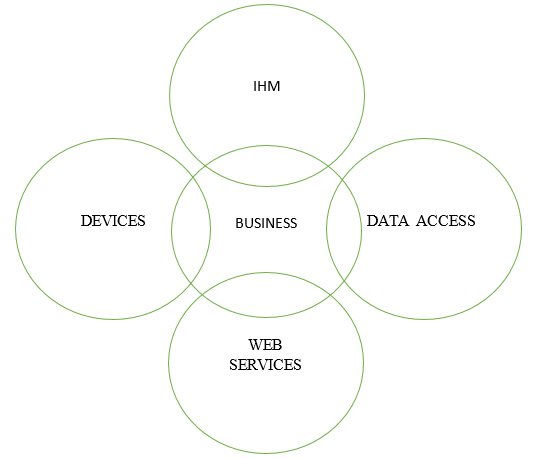
Nous voyons très clairement que le domaine de responsabilité
business est l’élément central de notre système. Si on y réfléchi bien c’est
même le seul périmètre dont nous aurions besoins si nos programmes se suffisaient
à eux-mêmes.
Malheureusement, un logiciel métier doit présenter des
données à des utilisateurs, en sauvegarder d’autres de manière organisée dans
des bases de données, interagir avec des périphériques ou des systèmes
externes, etc. Autant de domaines de responsabilités différents qui font des
logiciels de gestion de véritables monstres qui peuvent très vite asservir leurs
développeurs en esclavage s’ils ne sont pas bien maîtrisés.
Mais attention, tous ces autres domaines ne doivent pas être
considérés comme faisant partie de la partie business. Ce ne sont que des
composants proposant des entrées et des sorties avec le domaine principale.
Cette nuance est très importante car le chevauchement des
périmètres de responsabilité amène généralement les développeurs à faire du
« fixture code » qui peut rapidement rendre les modules fortement
couplés entre eux.
La solution que je propose consiste donc à partir sur une
architecture en oignon un peu particulière.
 Explication
Explication
Cette architecture englobe trois concepts principaux qui
sont les suivants :
- La partie business (en bleu) qui est le centre de l’architecture. Physiquement, c’est un projet (une DLL) qui possède toutes les API permettant de manipuler du métier pur. Ici on trouve des classes factures, personnes, monnaies, des factorys permettant d’obtenir des entités purement métier.
- La partie contrats (en jaune) est une zone dans laquelle ne se trouve AUCUN CODE. Physiquement, ce sont des projets dans lesquelles on ne trouve que des interfaces. Nous verrons plus tard que ces interfaces devront être écrites d’une manière particulière pour être en adéquation avec notre principe d’indépendance totale.
- La partie périphérique (en vert) possède les implémentations des contrats (en jaune). Chaque périphérique est un projet spécifique qui doit implémenter tous les contrats qui le concerne. Le développeur du projet a aussi la charge de mettre en place l’environnement de test qui permettra de valider la bonne implémentation de son code.
Bien que le sujet soit très intéressant, je ne vais pas
m’attarder sur cette architecture et comment la mettre en place, car je vais
partir du principe que vous connaissez déjà
toutes les bonnes pratiques permettant de mettre en œuvre un système
SOLID.
Si on prend par exemple l’interconnexion entre la partie Business
et la partie SQL Server, toutes les deux ne sont référencées qu’a un seul
projet : le « Data Access
Contract ». Elles ne se connaissent donc pas l’une et l’autre.
Cela signifie que la partie business possédera une classe
« Personne » qui ressemblera très fortement à une autre classe
« Personne » située dans la partie SQL. Mais quel est l’intérêt de
toute cette tuyauterie ? Comment allons-nous pouvoir manipuler les
objets d’un monde à l’autre ? Cela ne fait-il pas redondance ? Je
vais essayer de répondre à ces questions…
Quel est l’intérêt
de toute cette tuyauterie ?
Ce système qui peut paraitre lourd au premier abord apporte
énormément d’avantages :
- Partager le travail : un groupe de développeur peut travailler sur la partie purement business tandis qu’un autre travaille sur un périphérique sans aucune interférence ni effet de bord possible. Plusieurs équipes peuvent alors travailler de façon verticale sur le même sujet mais à des niveaux différents.
- Changement d’un comportement sans danger : Vous devez migrer votre SGBD en mode NoSQL ? Votre fournisseur Webservice passe en LDAP ? Une prochaine mise à jour va nécessiter de revoir les appels à un périphérique ? Votre IHM doit repasser en Winform ? pas de problème ! Grâce au couplage inexistant entre vos domaines de responsabilités, le fait de changer l’implémentation d’un projet périphérique n’aura aucun impact sur votre partie business (ni sur les autres périphériques d’ailleurs). Vous pourrez garder le focus sur la ré-implémentation du domaine ciblé sans vous soucier des effets de bords possibles. De quoi se permettre tous les délires.
- Implémentations multiples : Votre logiciel doit travailler sur plusieurs types de bases de données ? switcher entre Oracle, SQL Server et un fichier Excel local ? Supporter plusieurs IHM en fonction qu’il soit exécuté sur une machine de bureau ou une tablette Surface ? Une fois encore, les contrats vont vous permettre de jouer avec plusieurs implémentations grâce à l’injection de dépendance.
- Recherche et correction de bug : Les exceptions non gérées ainsi que les bugs de fonctionnement sont plus rapidement identifiés et corrigés du fait que chaque domaine de responsabilité possède son propre arsenal de tests spécifiques.
Comment allons-nous
manipuler les objets d’un monde à l’autre ?
Pour répondre à cette question, je vais en premier lieu
exposer le principe de base :
Lorsqu'un programmeur désire faire une vraie séparation
entre deux domaines, celui-ci n’a pas d’autre choix que de créer des entités
spécifiques à chaque domaine.


Grâce à ce contrat, nous sommes en mesure de nous assurer
que lorsque les deux domaines parlent d’une personne, ils sont tous les deux
d’accord sur le fait qu’il s’agit d’une entité possédant un nom et une date de
naissance. Toutes les autres propriétés ne sont
que des informations propres à leur logique interne et ne concerne en
aucun cas les autres domaines.
Mais comment faire pour appliquer le comportement de PersonA
lorsque DomainA obtient une instance de PersonB ? C’est très simple :
il suffit de faire une copie de PersonB dans une nouvelle instance de PersonA.
Cette action de copier un objet vers un autre objet de type différent pour
bénéficier de son comportement se nomme « la transformation ». C’est
justement le sujet de cet article !
Cela ne fait-il pas
redondance ?
Depuis votre tout premier programme, tout le monde vous
rabâche sans cesse qu’il faut factoriser le code. C’est d’ailleurs le principe
D de l’acronyme STUPID, à savoir la Duplication. Alors, faire plusieurs classes
pour représenter la même entité n’est-il pas de la duplication de code ?
Un programmeur
débutant serait fortement tenté de créer un projet spécifique dans lequel se
trouvent toutes les entités, puis il ferait en sorte que chacun des modules en ayant besoin accède à ce projet.
Non seulement ce raisonnement est une mauvaise idée, mais
c’est aussi une violation de plusieurs principes SOLID.
La duplication de code survient lorsque votre programme
appel des jeux d’instructions différents pour appliquer des comportements
équivalents. Cette mauvaise pratique force les programmeurs à passer sur chaque
jeu d’instructions lorsqu’il est nécessaire d’apporter une modification au
comportement voulu. Il est clair que ceci est une mauvaise pratique qu’il faut
absolument bannir de vos projets.
Mais qu’en est-il de notre cas ? Pensez-vous qu’une
entité « Personne » de votre logique métier a les mêmes comportements
qu’une entité « Personne » dans votre couche d’accès aux
données ? Assurément non !
Une « Personne » dans le métier possédera par
exemple des propriétés calculées comme l’âge qu’il avait à sa date
d’inscription au service, un numéro de téléphone correctement formaté ou une
liste de produits qui pourraient l’intéresser, tandis qu’une
« Personne » dans la couche d’accès aux données possédera quant à
elle des clés étrangères, un identifiant unique, des méthodes de résolution de
jointures, etc.
Nous ne sommes donc pas en présence de duplication de code,
car nous devons traiter des comportements différents. Il est donc parfaitement
logique pour une architecture SOLID que chaque comportement soit séparé dans
des classes différentes.
Choix du type de contrats
Maintenant que tout le monde a compris ce qui motive cet
article, attaquons nous au vif du sujet.
Notre but est de faire de la copie d’objets ayants des
structures différentes.
Pour savoir quels membres doivent être copiés, il est
nécessaire d’avoir une description des propriétés communes à chaque objet.
Cette description qui peut être sous plusieurs formes se nomme un contrat.
Ceux d’entre vous qui possèdent une expérience en WCF ont
surement déjà entendu parler de ce concept, car cette technologie propose une
API de DataContracts permettant de faire fonctionner les mécanismes de
sérialisations.
Si vous vous êtes intéressé à ces mécanismes, vous avez
surement cherché des moyens plus optimisés de mener à bien cette tâche, et vous
avez entendu parler d’autres systèmes de sérialisations par contrat comme protobuf.
Il existe aussi plein de méthodes permettant de faire de la
copie de champs équivalents grâce à la comparaison par réflexion.
L’une ces méthodes ne pourrait-elle pas remplir notre
besoin ?
En tant qu’architecte logiciel, votre rôle est de vous
assurer que votre programme est facilement compréhensible, manipulable et modifiable
par tous les développeurs qui seront amenés à travailler sur votre projet. Il
est donc très important de veiller à mettre en place des méthodes simples nécessitant un minimum
de formation, et qui laissent peu de place à l’erreur d’implémentation.
Or, que nous proposent les outils décrits
précédemment ?
Les DataContracts WCF travaillent avec des attributs. Faire
un contrat consiste à tagger chaque propriété pour que le système de
sérialisation soit en mesure de faire les correspondances adéquates. Une
architecture basée sur ce principe obligera les développeurs soit à maintenir
une documentation à jour, soit à créer un outil spécifique pour la conception
des contrats. Dans les deux cas, la lourdeur de cette technique est trop
assujettie à des oublis et ne permet pas de bénéficier du compilateur pour
détecter d’éventuelles erreurs.
Protobuff propose plusieurs techniques. L’une d’entre elle
consiste aussi à passer par des attributs. Nous ne retiendrons pas cette
méthode pour les raisons évoquées précédemment. L’autre consiste à créer un
fichier de description qui permettra avec un outil tiers de générer du code
spécifique.
Un nouveau développeur qui arrive sur le projet devra se
former à cet outil, à la syntaxe à utiliser, etc. Tout remaniement de code
nécessitera une recompilation par les outils tiers ce qui génère une fois de
plus du travail supplémentaire. Et bien sûr, cette technique ne permet pas de
bénéficier de la détection d’erreurs lors de la compilation.
Quant aux méthodes de copies génériques utilisant la
réflexion, je pense que ce n’est même pas la peine d’en parler, car comme vous
l’aurez compris elles ne nécessitent pas de contrat vu qu’elles se basent sur
la correspondance des noms et des types de propriétés pour effectuer leur
travail. Je vous laisse imaginer les effets de bord possibles lorsque quelqu’un
va renommer des propriétés ou revoir une hiérarchie de classe lors d’un remaniement
de code…
Alors que nous reste-t-il ?
Il nous reste les
interfaces, qui ont le mérite d’apporter plusieurs avantages :
- Elles sont natives au langage. Donc compréhensible par tous sans formation supplémentaire.
- Elles peuvent être utilisées par des outils de manipulation de code (comme resharper), ce qui va permettre de générer rapidement les implémentations, faire du renommage massif, de la navigation dans le code, etc.
- Elles génèrent des erreurs de compilation, ce qui laisse peu de doute au programmeur quant à la façon de les implémenter.
- Elles respectent les principes de la POO
En tant qu’architecte, c’est donc visiblement le meilleur
choix pour nous permettre de créer des contrats qui respectent nos prérequis.
Structurer des interfaces pour qu’elles remplissent leur rôle de contrat.
Si vous faites quelques recherches sur internet, vous
remarquerez que l’utilisation d’interfaces pour aider à faire de la copie
d’objets est quelque chose de très peu répandu. Mais pourquoi ? N’est-ce
pas un moyen simple et naturel de créer une description de structure ?
Malheureusement, c’est bien plus compliqué qu’il n’y parait,
et je vais essayer de vous en exposer les raisons.
Lorsque j’utilise une interface pour décrire une structure
en vue de faire de la copie, tout se passe bien tant que je ne travaille
qu’avec des types de base (string, int, DateTime, …)
Les premiers problèmes commencent à apparaître lorsque notre
structure doit contenir une autre structure.
Dans ce cas, l’implémentation naïve consiste à placer directement
dans notre première interface un nouveau membre qui sera du type de l’interface
agrégée.
Exemple :
public interface IPerson
{
string FirstName { get; set; }
string LastName { get; set; }
IAddress Address{ get; set;}
}
public interface IAddress
{
string Street { get; set; }
string City { get; set; }
string Country { get; set; }
}
Ici, notre contrat IPerson
doit contenir une adresse. Nous avons
donc créé un contrat IAddress puis
ajouté un membre de type IAddress
dans IPerson
Cela est parfaitement logique pour tout bon programmeur C#
Passons à une première implémentation de ces contrats dans
un domaine A :
public class PersonA : IPerson
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public IAddress Address { get; set; }
}
public class AddressA : IAddress
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
}
Nous voyons dans l’implémentation de PersonA que nous avons un membre de type IAddress. Vous conviendrez qu’il serait préférable que ce type soit
directement un AddressA pour que la
manipulation de l’objet PersonA soit
plus aisée.
Malheureusement, cela n’est pas possible malgré le fait que
la classe AddressA implémente IAddress car une implémentation
d’interface demande le type exact déclaré dans celle-ci.
Bien sûr, plusieurs contournements sont possibles comme par
exemple déclarer un membre nommé Address
de type AddressA, puis implémenter
notre membre d’interface de façon explicite pour pouvoir manipuler ce membre :
public class PersonA : IPerson
{
public AddressA Address = new AddressA();
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
IAddress IPerson.Address
{
get { return Address; }
set {
if( !(value is AddressA) )
throw new Exception("Cannot assign the property because is does not have the matching type AddressA");
Address = (AddressA)value;
}
}
}
Mais cette technique pose plusieurs problèmes. Déjà elle nécessite de taper plusieurs lignes de codes de programmation défensive, ensuite elle crée des propriétés qui font double emploi avec notre membre d’interface et enfin elle alourdie nos mécanismes qui permettront par la suite de faire de la copie.
Une autre problématique plus ou moins du même type se
présente aussi lorsque notre contrat doit contenir des collections d’objets.
Comme nos contrats ne doivent pas posséder de membre
fortement typé (car nous devons rester indépendant de toutes les couches
adjacentes), la solution qui vient à l’esprit est d’utiliser des IEnumerable
pour représenter nos collections.
public interface IPerson
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
IEnumerable<IAddress> Address { get; set; }
}
Mais comme pour les agrégations, cette technique apporte un lot de problèmes important, car non seulement elle nécessite de faire du remapping de propriétés en interne, mais en plus nous ne pourrons pas synchroniser nos collections du fait que nous les avons déclarées dans le contrat en «lecture seule »
Mais alors quelles est la meilleure solution à
adopter ?
La bonne méthode consiste à utiliser des types génériques
avec contraintes dans vos interfaces.
public interface IPerson<TAddress> where TAddress : IAddress
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
TAddress Address { get; set; }
}
Ainsi, lorsque vous passerez à l’implémentation, vous n’aurez plus qu’à déclarer le type voulu dans le générique, et le tour est joué !
public class PersonA : IPerson<AddressA>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public AddressA Address { get; set; }
}
En ce qui concerne les collections, nous appliquerons la
même technique à la différence que la contrainte doit se faire sur le type
ICollection
Exemple avec une classe « Person » qui doit
contenir plusieurs numéros de téléphones :
public interface IPhone
{
string Number { get; set; }
string Type { get; set; }
}
public interface IPerson<TAddress, TPhone, TCollectionPhone>
where TAddress : IAddress
where TPhone : IPhone
where TCollectionPhone : ICollection<TPhone>
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
TAddress Address { get; set; }
TCollectionPhone Phones { get; set; }
}
Ce type de contrat révèle toute sa puissance pour la
transformation de données entre la couche business et la couche IHM, car la
plupart du temps, la couche business a besoin de simples listes génériques
tandis que les entités IHM ont besoins de collections observables afin d’être
facilement liées aux vues.
Grâce à ce contrat générique, les deux mondes peuvent
implémenter l’interface en déclarant d’un côté une List<BusinessPhone> et de l’autre côté une ObservableCollection<UiPhone>.
Cela ne posera aucun problème pour le système de transformation, bien au
contraire !
Mais comment ça se passe si nos sous-types contiennent aussi
des sous-types pour faire les contrats correspondants ?
La meilleure méthode dans ce cas est de séparer notre
contrat en deux interfaces (ou plusieurs).
Une première interface de base possédera tous les membres
ayant un type de base, et la deuxième tous les membres possédants les types
génériques. Ainsi nous pourrons appliquer des contraintes de types en se basant
sur l’interface de base ce qui permettra d’éviter d’avoir à déclarer tous les
génériques lors l’implémentation.
Imaginons par exemple que nous devions ajouter des
coordonnées GPS à notre adresse. Les contrats deviendraient alors :
public interface IGpsLocation
{
double Latitude { get; set; }
double Longitude { get; set; }
}
public interface IAddress
{
string Street { get; set; }
string City { get; set; }
string Country { get; set; }
}
public interface IAddress<TGpsLocation> : IAddress
where TGpsLocation : IGpsLocation
{
TGpsLocation GpsLocation { get; set; }
}
Et au niveau de l’implémentation dans notre domaine A :
public class GpsLocationA : IGpsLocation
{
public double Latitude { get; set; }
public double Longitude { get; set; }
}
public class AddressA : IAddress<GpsLocationA>
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
public GpsLocationA GpsLocation { get; set; }
}
public class PersonA : IPerson<AddressA>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public AddressA Address { get; set; }
}
Ici notre classe PersonA reste très simple malgré le fait que
le contrat IAdresse possède un sous membre qui logiquement doit être défini à
cause du générique.
Pour résumer, si vous n’avez rien compris voici l’essentiel
à retenir :
- Les contrats sont des interfaces
- Les membres qui ne sont pas des types natifs doivent être déclarés sous forme de type générique.
- Les membres de types collection doivent aussi être déclarés sous forme de type générique avec une contrainte sur l’interface ICollection.
- Les interfaces génériques qui contiennent elles-mêmes d’autres interfaces génériques peuvent être séparées en deux parties. Une interface de base qui contient tous les membres natifs et une interface générique qui hérite de l’interface de base. Ainsi les contrats peuvent garder leur simplicité en ne déclarant que l’interface de base.
Le système de transformation
Maintenant que vous connaissez l’intérêt de bien isoler vos
couches avec des contrats, et comment construire ces contrats, nous allons
passer à la partie intéressante : le système de transformation.
Comme je l’explique depuis le début de cet article, l’objectif
est de copier des données issues d’un objet source dans un objet destination de
type différent.
Malheureusement, les logiciels de gestion doivent interagir
avec des bases de données, et la moindre des choses lorsque l’on travaille sur
un projet conséquent qui peut contenir plusieurs centaines de tables consiste à
utiliser un ORM pour pouvoir évoluer sereinement.
Or, la plupart des ORM fonctionnent de telle manière qu’ils
fournissent des objets matérialisés issues d’une base de données, et pour permettre
de générer la requête correspondante aux
modifications apportées à ces objets, des mécanismes de détection se basent
directement sur les instances de ces objets maintenus par un contexte interne !
Notre problème ne consiste donc pas qu’à faire de la simple
copie de données, mais à faire de la synchronisation de données et de grappe
d’objets pour rester conforme aux ORM.
Vous commencez maintenant à comprendre pourquoi les
architectes logiciels ne veulent pas se prendre la tête avec une vraie
séparation des domaines J
Ainsi, l’outil de transformation que je vais vous présenter
se nomme la MergeCopy, car le système permet non seulement de copier des objets
qui respectent un contrat commun, mais aussi de synchroniser la destination
avec les données source sans toucher à l’intégrité des instances d’objets qui
les constituent.
Utilisation
La MergeCopy se présente sous la forme d’une simple méthode
d’extension appelée « MergeCopy() ».
Pour pouvoir l’utiliser, ajoutez à votre contrat l’interface
générique IMergeableCopy<T>, T étant le type qui représentera
l’identifiant unique de l’instance de l’objet qui sera accessible via la
propriété « MergeId »
Cette propriété est un membre purement technique permettant
à la MergeCopy de distinguer une instance d’objet d’une autre instance pour un
même type afin de pouvoir effectuer la synchronisation.
La stratégie d’assignation de cette propriété reste à la
discrétion du développeur. Mais en générale celle-ci est mappée à la clé primaire
de l’objet issu du DAL.
Reprenons l’exemple expliqué dans la partie précédente.
Tout d’abords, je
rajoute l’interface IMergeableCopy<T> à nos contrats en prenant le parti
de dire que mes instances seront représentées par des Guid :
public interface IPerson : IMergeableCopy<Guid>
{
string FirstName { get; set; }
string LastName { get; set; }
DateTime BirthDay { get; set; }
}
public interface IPerson<TAddress, TPhone, TCollectionPhone> : IPerson
where TAddress : IAddress
where TPhone : IPhone
where TCollectionPhone : ICollection<TPhone>
{
TAddress Address { get; set; }
TCollectionPhone Phones { get; set; }
}
public interface IPhone : IMergeableCopy<Guid>
{
string Number { get; set; }
string Type { get; set; }
}
public interface IAddress : IMergeableCopy<Guid>
{
string Street { get; set; }
string City { get; set; }
string Country { get; set; }
}
public interface IAddress<TGpsLocation> : IAddress
where TGpsLocation : IGpsLocation
{
TGpsLocation GpsLocation { get; set; }
}
public interface IGpsLocation : IMergeableCopy<Guid>
{
double Latitude { get; set; }
double Longitude { get; set; }
}
Maintenant que mes contrats sont parfaitement définis, je
vais pouvoir passer à l’implémentation dans deux domaines à responsabilités
différentes :
- BusinessDomain aura la responsabilité de fournir des Api pour créer et manipuler des personnes
- StorageDomain aura quant à lui la responsabilité de sérialiser et desérialiser ces objets dans un fichier texte possédant un format spécifique.
Je rappelle que physiquement, BusinessDomain et
StorageDomain sont deux DLL bien distinctes qui référencent toutes les deux nos
contrats qui eux-mêmes sont dans une troisième DLL.

Implémentation dans la partie Business :
En premier lieu, je vais créer une classe de base pour
centraliser la gestion de notre MergeId :
public abstract class Business : IMergeableCopy<Guid>
{
protected Business()
{
MergeId = Guid.NewGuid();
}
public Guid MergeId { get; set; }
}
J’implémente ensuite les contrats qui ne nécessitent pas de
types génériques :
public class BusinessPhone : Business, IPhone
{
public string Number { get; set; }
public string Type { get; set; }
}
public class BusinessGps : Business, IGpsLocation
{
public double Latitude { get; set; }
public double Longitude { get; set; }
}
Une fois ces classes implémentées, je peux passer à celles
qui les utilisent :
public class BusinessAddress : Business, IAddress<BusinessGps>
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
public BusinessGps GpsLocation { get; set; }
}
public class BusinessPerson : Business, IPerson<BusinessAddress, BusinessPhone, List<BusinessPhone>>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime BirthDay { get; set; }
public BusinessAddress Address { get; set; }
public List<BusinessPhone> Phones { get; set; }
}
Très bien, apportons maintenant quelques comportements spécifiques à nos objets business
public class BusinessPerson : Business, IPerson<BusinessAddress, BusinessPhone, List<BusinessPhone>>
{
private string _lastName;
public string FirstName { get; set; }
public string LastName
{
get { return _lastName; }
set
{
if( string.IsNullOrWhiteSpace(value) )
throw new Exception("The lastname cannot be empty");
_lastName = value.ToUpper();
}
}
public DateTime BirthDay { get; set; }
public BusinessAddress Address { get; set; }
public List<BusinessPhone> Phones { get; set; }
public int Age { get { return DateTime.Now.Year - BirthDay.Year; } }
}
La propriété « LastName » ne peut pas être vide et
est convertie en majuscule lorsqu’elle est définie. Aussi une nouvelle
propriété « Age » a été ajoutée pour calculer l’âge de la personne en
fonction de sa date de naissance.
Implémentons maintenant la partie Storage
public class StoragePerson : Storage, IPerson<StorageAddress, StoragePhone, List<StoragePhone>>
{
public string FirstName { get; set; }
public string LastName{ get; set; }
public DateTime BirthDay { get; set; }
public StorageAddress Address { get; set; }
public List<StoragePhone> Phones { get; set; }
public override string ToString()
{
var builder = new StringBuilder(FirstName + "^" + LastName + "^" + BirthDay + "^" + (Address != null ? Address.ToString() : ""));
foreach (var storagePhone in Phones)
builder.Append("|" + storagePhone);
return builder.ToString();
}
}
public class StorageAddress : Storage, IAddress<StorageGps>
{
public string Street { get; set; }
public string City { get; set; }
public string Country { get; set; }
public StorageGps GpsLocation { get; set; }
public override string ToString()
{
return Street + "^" + City + "^" + Country + "^" + (GpsLocation != null ? GpsLocation.ToString() : "");
}
}
public class StoragePhone : Storage, IPhone
{
public string Number { get; set; }
public string Type { get; set; }
public override string ToString()
{
return Number + "^" + Type;
}
}
public class StorageGps : Storage, IGpsLocation
{
public double Latitude { get; set; }
public double Longitude { get; set; }
public override string ToString()
{
return Latitude + "^" + Longitude;
}
}
public abstract class Storage : IMergeableCopy<Guid>
{
protected Storage()
{
MergeId = Guid.NewGuid();
}
public Guid MergeId { get; set; }
}
Comme vous pouvez le constater, ici notre but est de générer
une ligne par personne qui aura le format suivant :
FirstName^Lastname^BirthDay^Street^City^Country^Latitude^Longitude|Number^Type|Number^Type|…
Mais une question se pose : comment la partie business
va pouvoir envoyer l’ordre à la partie storage de procéder à l’enregistrement
de son objet ?
Effectivement, cet article étant porté sur la copie de
données, je me suis principalement axé sur la problématique de DTO (Data
Transfert Object) qui se pose entre nos modules. La question de savoir comment
envoyer les ordres entre les modules est plus une question d’architecture
générale sur laquelle vous pourrez trouver d’excellentes réponses grâce à
l’utilisation des « Services » et des « Repository »
Dans notre cas, la DLL qui contient les contrats possède
aussi les interfaces qui définissent comment doivent être implémenté les
repository. La différence fondamentale, c’est que seule la partie Storage
implémentera le repository. La partie business pourra y accéder grâce à un
mécanisme d’injection de dépendance, ce qui n’est pas du tout le sujet de cet
article.
Pour notre exemple, voici à quoi ressemble l’interface de
notre Repository :
public interface IStorageRepository
{
void SavePerson(string filePath, IPerson person);
}
L’implémentation que nous en ferons dans la partie Storage
sera celle-ci :
public class StorageRepository : IStorageRepository
{
public void SavePerson(string filePath, IPerson person)
{
var personToSave = new StoragePerson();
personToSave.MergeCopy(person);
File.AppendText("\r\n" + personToSave);
}
}
Quelques explications s’imposent :
Le repository a pour fonction d’enregistrer notre personne
dans un fichier texte, mais comme vous pouvez le voir, l’argument est un
IPerson, ce qui signifie que l’objet qui sera passé n’aura pas le comportement
qui permet au storage de formater la chaine comme expliqué précédemment.
Nous devons donc transformer cette IPerson en un
StoragePerson, c’est donc le rôle des deux lignes de code qui sont :
var personToSave = new StoragePerson(); personToSave.MergeCopy(person);
Une fois que nous sommes en possession d’une StoragePerson,
il devient alors facile de l’enregistrer dans le fichier demandé.
Pour obtenir l’effet inverse, c’est-à-dire de disposer d’une
BusinessPerson à partir d’un StoragePerson désérialisé, il suffit de faire la
même chose dans le service utilisé par la partie Business.
Par exemple si je fais évoluer mon Repository de la façon
suivante :
public interface IStorageRepository
{
IPerson Load(Guid personId);
void SavePerson(string filePath, IPerson person);
}
En imaginant que la partie Storage implémente le Load, je
vais créer dans la partie Business un service qui permettra de manipuler le
Repository :
public interface IBusinessService
{
BusinessPerson GetPerson(Guid id);
void SavePerson(BusinessPerson person);
}
public class BusinessService : IBusinessService
{
private readonly IStorageRepository _storageRepository;
public BusinessService(IStorageRepository storageRepository)
{
if (storageRepository == null) throw new ArgumentNullException("storageRepository");
_storageRepository = storageRepository;
}
public BusinessPerson GetPerson(Guid id)
{
var storageObject = _storageRepository.Load(id);
BusinessPerson result = new BusinessPerson();
result.MergeCopy(storageObject);
return result;
}
public void SavePerson(BusinessPerson person)
{
_storageRepository.SavePerson("d:\\database.txt",person);
}
}
Comme vous le voyez dans la méthode GetPerson(), nous
récupérons un enregistrement issu du storage, puis nous le transformons en
BusinessPerson. Avec à cette stratégie, notre service est en capacité de ne
traiter plus que des BusinessObject.
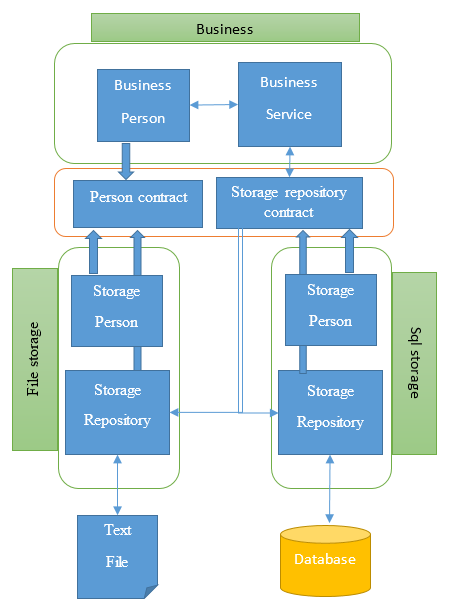
Cet exemple nous a permis de mettre en place l’architecture
suivante :

Grâce au découplage total que cela apporte, nous pouvons
imaginer plusieurs sortes de substitution, comme par exemple :
Remplacer la partie storage par un objet simulacre afin de
pouvoir tester la partie business

Ajouter en parallèle un deuxième repository qui permettrait
d’enregistrer nos objets dans une base de données plutôt que dans un fichier
texte
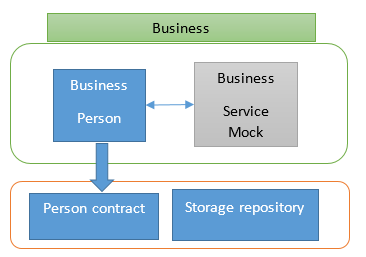
Ou tout simplement tester certaines logiques internes de la
partie business en remplaçant le service par un objet simulacre.
Une telle malléabilité ouvre un grand champ d’éventualités pour
les architectes. Pour peu que vous vous intéressiez au Behavior Driven
Developpement, sachez que cela vous donne la possibilité de faire des
applications business avec des scénarios de tests qui viendront alimenter
certains enregistrements dans une base de données complétement virtuelle. De
quoi garantir la robustesse et la non régression de votre logiciel à tout
instant !
Mais cela est encore un nouveau sujet…
Pour revenir à nos moutons, voici quelques dernières choses
à savoir sur la MergeCopy :
- La bonne gestion du MergeId ne permet pas seulement de régler les cas de fusions d’instances, mais permet aussi de régler les problèmes de type enfant qui pointe vers son parent. Donc pas d’inquiétude en ce qui concerne les boucles infinies qui peuvent se produire dans d’autres systèmes de copie.
- En tant que système central de votre architecture, La MergeCopy possède plusieurs systèmes d’optimisation pour que la copie ne ralentisse pas trop votre application. Toutefois des objets trop gros ou trop complexes qui sont très souvent transformés peuvent avoir un impacte sur les performances. Soyez donc vigilent sur ce point.
Une dernière chose dont nous n’avons pas parlé concerne
l’ordre de copie des propriétés. Car il arrive parfois qu’une propriété
s’appuie sur une autre propriété pour faire des contrôles d’intégrités, par
exemple :
public class BusinessAddress : Business, IAddress<BusinessGps>
{
private string _city;
private string _country;
private BusinessGps _gpsLocation;
public string Street { get; set; }
public string City
{
get { return _city; }
set
{
if(string.IsNullOrWhiteSpace(Street))
throw new Exception("Define street before the city");
_city = value;
}
}
public string Country
{
get { return _country; }
set
{
if (string.IsNullOrWhiteSpace(City))
throw new Exception("Define city before the country");
_country = value;
}
}
public BusinessGps GpsLocation
{
get { return _gpsLocation; }
set
{
if( string.IsNullOrWhiteSpace(Street) || string.IsNullOrWhiteSpace(Country) || string.IsNullOrWhiteSpace(City) )
throw new Exception("define all the properties before the gps location");
_gpsLocation = value;
}
}
}
Ici la règle métier veut que la rue soit renseignée avant la
ville, que la ville soit renseignée avant le pays et que la localisation GPS ne
soit renseignée que lorsque toutes les données sont préalablement définies.
Si la MergeCopy ne procède pas dans le bon ordre, celle-ci
va échouer inévitablement.
Pour pallier ce problème, la MergeCopy propose un attribut
nommé [MergeCopy] à placer sur les propriétés de vos classes.
Cet attribut peut être exploité de plusieurs manières :
En utilisant la propriété Order
Avec cette propriété, vous pouvez définir l’ordre exact dans
lequel la copie doit s’effectuer. Plusieurs propriétés peuvent avoir le même « order ».
Exemple :
public class BusinessAddress : Business, IAddress<BusinessGps>
{
private string _city;
private string _country;
private BusinessGps _gpsLocation;
[MergeCopy(Order = 1)]
public string Street { get; set; }
[MergeCopy(Order = 2)]
public string City
{
get { return _city; }
set
{
if(string.IsNullOrWhiteSpace(Street))
throw new Exception("Define street before the city");
_city = value;
}
}
[MergeCopy(Order = 3)]
public string Country
{
get { return _country; }
set
{
if (string.IsNullOrWhiteSpace(City))
throw new Exception("Define city before the country");
_country = value;
}
}
[MergeCopy(Order = 4)]
public BusinessGps GpsLocation
{
get { return _gpsLocation; }
set
{
if( string.IsNullOrWhiteSpace(Street) || string.IsNullOrWhiteSpace(Country) || string.IsNullOrWhiteSpace(City) )
throw new Exception("define all the properties before the gps location");
_gpsLocation = value;
}
}
}
En utilisant la propriété StackBottom
Il arrive dans certains cas que l’on désire qu’une ou
plusieurs propriétés soient copiées en premier ou en dernier quoi qu’il arrive.
La MergeCopy considère l’ensemble des propriétés d’un objet
à copier comme les éléments d’une pile. En jouant avec StackBottom et order,
vous pouvez dire si la propriété à copier se trouve sur le haut ou sur le bas
de la pile.
Schéma :

Voilà, je pense que vous savez tout.
Conclusion
La méthode que je vous ai présentée ici a été mise en œuvre
sur un logiciel de gestion dans le domaine de la santé que plusieurs personnes sont amenées à faire
évoluer en ajoutant de nouveaux modules au fil de l’eau.
Grâce au découplage total qu’apporte la transformation, des
équipes différentes travaillent sur plusieurs aspects du logiciel qui s’avèrent
être les composants d’une seule et même fonctionnalité métier. Chaque élément
est ainsi testé indépendamment, et un système d’injection de dépendance
assemble tous les morceaux pour la plus grande joie des utilisateurs.
Le système de contrat agit comme une sorte de spécification
entre les développeurs, ce qui leur permet de se mettre d’accord sur les API
qui doivent être fournies. Toute modification du contrat est ainsi détectée au
moment de la compilation amenant plus de communication entre les développeurs si
des évolutions sont apportées aux API.
Mais la MergeCopy seule ne fait pas tout. Pour en tirer
pleinement parti vous devrez maitriser tous les patterns permettant de mettre
en œuvre une bonne architecture SOLID.
Le sujet est vaste et plein d’embuche, mais ce n’est qu’à ce
prix que vous pourrez mettre sur le marché des logiciels pour lesquelles
les utilisateurs apprécieront chaque
mise à jour que vous leur fournirez.

Bon article M. Boudoux. Ca me rappelle beaucoup de souvenirs ;)
RépondreSupprimerDepuis quelques mois, j'ai pu prendre du recul sur cette architecture à laquelle j'ai pu participer. J'ai quelques remarques :
1) L'architecture est fondée initialement sur la copie entre des objets métiers dit "purs" et des objets de base de données générés par Entity Framework. Mais a-t-on vraiment besoin de générer les objets Entity ? Qu'en tire-t-on vraiment ? En réalité, les classes de mapping ont été conçues initialement pour pouvoir décrire le lien entre des objets métiers et la base de données. Dans la DAL, il est donc possible de crééer du mapping directement avec les objets du domaine. Plus besoin d'objet intermédiaire Entity qui n'ont en fait aucun intérêt, et donc plus de couche intermédiaire de contrat.
2) Dans des projets importants (disons plus que gros), il est très fortement déconseillé d'utiliser des ORM comme EntityFramework ou NHibernate pour gérer la persistance, surtout si l'on exploite pas réellement leur capacité de tracer les propriétés modifiées au cours du temps. Il existe des MicroOrms extrèmement puissants et performants permettant de générer les requêtes. Plus besoin de couche intermédiaire car on persiste directement l'objet du domaine.
3) Le problème d'exposer un contrat du domaine, c'est qu'on expose sa complexité. Dans ton exemple, on expose la structure interne du domaine via ses contrats. (La Personne, son Adresse, son Téléphone et les liens métiers). On risque donc de complexifier les intéractions avec les autres acteurs car ces derniers doivent créer une classe qui implémente le contrat du domaine ! En toute théorie, le domaine est sensé n'être exposé à aucun acteur externe (On considère la DAL comme étant un acteur interne). Toute la complexité métier d'agencement des concepts, des règles d'intégrité, etc. doit être masquée. La communication avec le monde extérieur se fait avec les objets DTO (Data Transfert Object) qui sont des objets simplifiés du domaine (plus ou moins à plat). Ses objets sont en quelques sortes un contrat avec un ou plusieurs acteurs externes. Dans ce cas précis, il est nécessaire de faire une conversion entre l'objet DTO et les objets du domaine qu'il représente.
4) Plus j'y pense, et plus je me dis qu'extraire les contracts du domaine dans une autre assembly n'apporte pas grand chose tant que tu n'as qu'un seul module métier. Il empêche juste un composant externe d'appeler du code dans le domaine. Mais si le domaine est bien structuré, la plupart des classes métiers sont "internes" à l'assembly. Il n'y a donc pas réellement de plus-value. Par contre dans une architecture modulaire, on retrouve cette réflexion : chaque module expose ses contrats dans une autre assembly et ne pointe que vers les assemblies des contrats des autres modules. De cette manière, il n'y a pas de couplage fort. C'est le principe utilisé pour faire communiquer les Bounded Contexts en DDD.
De manière générale, le raisonnement que tu tiens est très proche de l'architecture classique DDD ou Onion (hexagonale). Je pense que l'adaptation que tu en as fonctionne très bien car vous êtes dans un contexte d'une application client lourd (lourd de chez lourd car pas de serveur applicatif). Le jour où votre domaine sera coté serveur et plus coté client, ça sera très différent !
-----
Pour continuer la réflexion, et si tu as le temps, je te recommande un bon article sur le DDD n-layered en .NET :
http://blogs.msdn.com/b/cesardelatorre/archive/2010/03/26/our-brand-new-ddd-n-layer-net-4-0-architecture-guide-book-and-sample-app-in-codeplex.aspx
C'est une réflexion client/serveur mais très intéressante.
Et comme du code vaut mieux qu'un long discours, des examples d'architecture sur codeplex : DDD, CODEDDD, DDDSAMPLE.NET ici :
http://www.codeplex.com/site/search?query=DDD
Salut Pierre, et merci pour ton commentaire :)
RépondreSupprimerAlors, je n’ai peut-être pas très bien compris, mais la première chose qui me frappe est de vouloir créer un mapping du DAL directement avec les objets du domaine. Je vois déjà plusieurs problèmes avec cette réflexion :
1) On crée un couplage fort entre le domaine et la DAL (chose que l’on veut éviter à tout prix)
2) Les classes utilisées par le mapping ont beau être POCO, celles-ci comportent toujours des membres spécifiques utilisés pour générer des requêtes (notamment les identifiants) ne risque-t-on pas de tomber dans du god object ?
C’est contre l’esprit de séparation totale voulue par l’architecture.
Il est clair que le couple BOL / DAL peut apporter de la confusion au débat, surtout si nous intégrons EF dans nos échanges, ce qui n’est pas le sujet.
Personnellement les choses sont devenues beaucoup plus limpides lorsqu’il a été nécessaire d’intégrer d’autres modules extérieurs au logiciel.
Par exemple, nous avons eu besoin d’ajouter une fonctionnalité réglementaire s’appuyant sur un webservice qui utilise un serveur spéciale de l’assurance maladie. L’utilisateur devant renseigner plusieurs informations dans le logiciel pour « télétransmettre » du contenu à ce serveur.
La première chose qu’a demandée l’équipe travaillant sur la partie BOL / UI est : donne nous les contrats ! Sous-entendu qu’est-ce que je dois t’envoyer, et sous quelle format ?
Le contrat n’est donc pas là pour exposer la structure du domaine, mais pour structurer les échanges entre le fournisseur du module et son client (le développeur BOL). Dans la mesure où c’est au fournisseur de l’écrire, il expose donc plus ou moins la structure du module.
Dans mon cas, je me suis basé sur les spécifications de l’assurance maladie pour créer tous mes contrats, et sans écrire une seule ligne de code, je les ai fournis aux développeurs BOL.
Une fois les détails calés, nous n’avons presque plus communiqué. De mon côté, j’ai implémenté le Webservice, écrit plusieurs tests qui s’appuyaient sur un cahier des charges bien précis auquel était joint un serveur de test dédié par l’assurance maladie.
Lorsque tous mes tests étaient OK, j’ai appris en parallèle que l’équipe BOL / UI avait terminé son implémentation fonctionnelle guidée par des scénarios BDD qui simulaient l’accès au webservice.
Nous avons donc publié une version sur le banc de test, et comme par magie tout à fonctionné du premier coup, alors que je ne comprenais rien à l’IHM et aux fonctionnalités sur lesquelles j’étais en train de cliquer :p
Tout ça pour dire que cette solution est tout de même pas mal, même si je sais que le DDD doit très certainement apporter des concepts encore bien plus poussés. J’avoue ne pas encore m’être intéressé vraiment au sujet, mais le peu que j’en ai compris, c’est que le gap entre faire du SOLID et du DDD est le même qu’entre faire de la POO et du SOLID.
With programming, it’s always beginning again !
Bonjour et merci pour cet article. Si j'arrive à l’implémenter, cela solutionnera mon pb.
RépondreSupprimerJ'ai une structure du genre: 1 Dossier contient:
1 Créance
1 Titre Executoire
1 Créancier
1 Débiteur (on verra n après...)
Le créancier et le débiteur implémentent ITiers
tout fonctionnait bien jusqu'à l'ajout du dossier où le compilateur me dit
The type 'MergeCopyFramework.UI.BusinessModels.BusinessDebiteur' cannot be used as type parameter 'TDebiteur' in the generic type or method 'MergeCopyFramework.UI.Contracts.IDossier'. There is no implicit reference conversion from 'MergeCopyFramework.UI.BusinessModels.BusinessDebiteur' to 'MergeCopyFramework.UI.Contracts.ITiers'.
Je peux te faire passer mon code si tu veux car je ne comprends pas: est ce parce que Debiteur et Créancier implementent ITiers
Davy Isbert
public interface IDossier
RépondreSupprimer{
int NumeroDossier { get; set; }
string AffaireEnClair { get; set; }
}
public interface IDossier : IDossier
where TCreance : ICreance
where TTitreExecutoire : ITitreExecutoire
where TDebiteur : ITiers
where TCreancier : ITiers
{
TCreance Creance { get; set; }
TTitreExecutoire TitreExecutoire { get; set; }
TDebiteur Debiteur { get; set; }
TCreancier Creancier { get; set; }
}
public class BusinessDossier : Business, IDossier
RépondreSupprimer{
public int NumeroDossier { get; set; }
public string AffaireEnClair { get; set; }
public BusinessCreance Creance { get; set; }
public BusinessTitreExecutoire TitreExecutoire { get; set; }
public BusinessDebiteur Debiteur { get; set; }
public BusinessCreancier Creancier { get; set; }
L'éditeur à supprimé des infos:
RépondreSupprimerIDossier < TCreance, TTitreExecutoire, TDebiteur, TCreancier > : IDossier
BusinessDossier : Business, IDossier < BusinessCreance, BusinessTitreExecutoire, BusinessDebiteur, BusinessCreancier >
public class BusinessDebiteur : Business, ITiers < BusinessAdresse >
RépondreSupprimerHello, et merci de ton intérêt pour cet article :p
RépondreSupprimerA première vue, j'ai l'impression que tes contrats n'implémentent pas l'interface IMergeableCopy.
IDossier, ICreance, ITiers, etc... doivent tous hériter de cette interface pour que la MergeCopy fonctionne.
Si vraiment tu galères, envoie moi ton code à aurelien@boudoux.fr pour que je jette un œil.
Bonne chance et @+
It is important to notice, however, that while utilizing a VPN doesn’t violate most playing sites’ Terms of Use, it may if you’re primarily putting bets outdoors the country 메리트카지노 during which you’ve established your account. Please exercise a basic degree of caution when utilizing a VPN in South Korea. Nowadays, the playing industry generates over 40% of the GDP of Macau. Since the early Nineteen Sixties, round 50% of Macau's official income has been pushed by playing. In 1998, forty four.5% of whole government income was produced by the direct tax on playing. Then there was a 9.1% decrease in 1999, most likely end result of} web gaming.
RépondreSupprimer